Database replication as a scalability tactic in Relational Databases
Intro to Database Replication in Relational Databases
I would like to call Replication the twin brother of Duplication. Even though these words are interchangeable most of the time they can't be interchanged all the time. Let's look at an excerpt from this Stack Exchange answer
If I'm a good painter, I can replicate the Mona Lisa, I cannot 'duplicate' it! So, to answer this question, check twice before interchanging these words.
Likewise, when you lose your original driving license or any other document, you apply for a duplicate copy. There, 'replica' does not work!
When your App starts to have performance issues with an increase in the number of requests, database replication is one quick way to breathe a little bit of performance into your app. a Database replica is a duplicate copy of your database. But it's replicated meaning the data is reproduced in the replica the same way it was initially created in the original database.
In this write-up, I would like to focus more on the replication technique of Relational databases like MySql, Postgres, etc. Also called a Read Replica, as the name suggests the replicas are read-only. Just because I can simply touch the idea of replication alone and don't have to write about Clusters, Leadership, Quorum, Election, etc... but could be a possibility in another post.
Application of Database Replication
Database replicas are an excellent way of offloading a heavy number of requests from a database. A replica is another database instance/server of usually the same configuration (at least the storage capacity) let us look into a simple Single Master Single Slave setup for a database and see how it functions
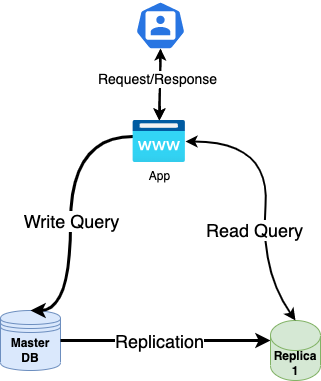
The main database called Master has a replica called Replica 1, The user is interacting through the App with the database, and it issues quite a number of database queries. All the write queries are going to the Master database initially and whatever data is inserted/updated/deleted will be replicated to the Replica 1 database Eventually. Later on, every read query is made to the Replica. This kind of configuration is one of the simplest and really helps to increase performance in a ready-heavy application by routing the read queries to another database and freeing up the Master database.
This replication configuration could be extended further by adding more replicas and forming a group of replicas. see the following figure
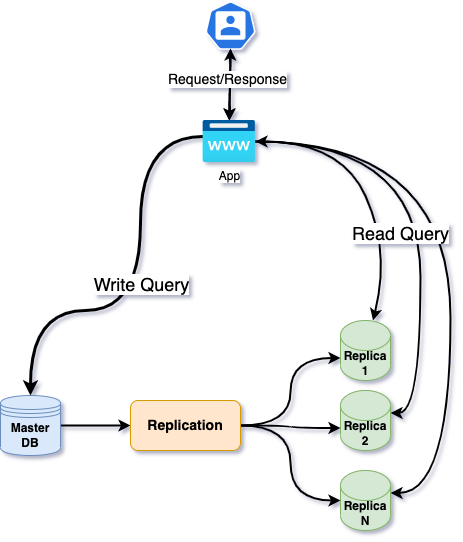
In this case, the write that happened in the master database is replicated into multiple replicas. The read queries are made to any of the replicas and the replica will respond with whatever latest data it has. We can use replicas to achieve High Availability and by deploying the replicas in multiple regions to avail Low Latency.
Usually, the replicas are used/consumed by the App by keeping different database connections to the Master and Replica(s). During a user request, the App chooses which connection to use, whether the Master connection is to do a write operation or a Replica connection to do a read operation. Another excellent choice would be to use replicas as the source of the Business Intelligence tool. You don't want heavy aggregations/operations being done to your master DB when you have users.
How replication is done
The replication could be done in two ways
- Synchronous
- Asynchronous
In synchronous replication, the database finishes the transaction only when both the Master and Slave(s) have the data. While this ensures the data is available/consistent across master and slave databases. Obviously, synchronous replication greatly reduces the write performance, especially when the replicas are not in the same data centre/region eg: Multi-AZ replicas.
While synchronous replication could be required in specific scenarios Asynchronous replication is my preferred way and it's the default for many cloud vendors including AWS. In asynchronous replication, the master completes the write and the changes are propagated to other replicas eventually. This is also a great weakness of replication and you can see that in the cons section.
The exact details of replication depend on the specific databases. But generally, the master DB produces the events for the operations that happened and these events (logs or binary data) are copied and replicated in the replicas, another way is to look for the primary keys in the tables and incrementally copy them.
Support for replication
Most relational databases have replication support.
- Mysql
- Postgres
- Microsoft SQL Server
- Oracle etc... are to name a few.
Major cloud providers also have managed replication solutions
Just a few clicks and you have a replication.
Pros of Database Replication
- Availability - Even when the Master DB is failed, the replica can still serve the users in a read-only mode.
- Disaster Recovery - In a situation of master DB failure, the replica can be promoted to a master fairly quickly and keep resuming the service. Most of the vendors have this failover support (Sometimes not fully automatic). Replicas can also act as a fairly decent backup.
- Performance - Database replication in theory could make your application perform very well in typical use cases.
- Simple - Replication is not a super complex topic to understand and is fairly quick to implement. While manual replication setup is not that simple, with modern cloud providers it is a matter of a few clicks to have the replication setup. Also, you can read a bit more about manual setup here. There are many 3rd party tools and providers that focus on replication technologies.
Cons of Database Replication
Database replication can be a quick way to add some performance to your apps and will serve you to great lengths in terms of performance. But it is not a silver bullet that solves all the problems, hence let us look at some limitations of database replication.
- Consistency - It is one of the biggest weaknesses of the replication. The chances of inconsistent data are very much of a problem. When the master has a write operation and for some reason, the operation is not propagated, the replica will respond with inconsistent data forever. To avoid this some kind of data integrity checks need to be deployed. And this is not really a trivial task. When an inconsistency is detected, fixing it would also not be trivial, especially in a big database with many foreign keys and stuff. Usually fixing inconsistency involves building a new replica and throwing the inconsistent replica away.
- Latency - When the user would not see his updated data in a mission-critical solution it would not take much time for him to look for another app. This is especially common in the case of multi-region replicas. For a user, his trivial activities are mission-critical and we want to show him his updates instantly. So it's important to monitor replication time and verify it's within acceptable limits. For example, I would use a master DB connection to manage his current order and probably will use a replica to pull the order history.
- Cost - This is something obvious. The replicas are their own new instances. You will pay for CPU, RAM and Storage. Even though you can have a smaller replica instance in terms of CPU or RAM, still storage needs to be the same as the original database.
Like I mentioned DB replication is not a solution for all your database problems, but it can be a wonderful addition to your toolbelt, and replication is supported by most of the mainstream database and cloud vendors. Let me know what you think about replication in Twitter @ppshobi